
The Stochastic Parrot at the Terminal: Why Autonomous LLM Trading is a Financial Larp
1. Introduction: The Current Larp Scene
The industry has a fascination with “magic beans,” and currently, those beans are labeled “Autonomous AI Agents.” Browse through X for more than five minutes, and you’ll inevitably hit the thread: a self-proclaimed “dev” giving a base-model LLM a hot wallet, 10 ETH, and a mandate to “trade the news.” The numbers that follow are always staggering, the charts are always up-and-to-the-right, and the engagement is always through the roof.
But if you peel back the slick UI of the latest viral trading bot, you don’t find a digital Soros—you find a next-token prediction engine that is fundamentally blind to market logic.
In the high-stakes world of treasury management and institutional crypto, mistaking a stochastic parrot for a professional trader isn’t just a mistake; it’s a structural liquidation risk. We are currently witnessing a massive “larp” (Live Action Role Play) where influencers mistake eloquent market commentary for technical execution competence.
We aren’t just hating for the sake of it. In this piece, we’re going to look at the mechanics—the cold, probabilistic math that makes LLMs fundamentally unfit for independent execution. If you don’t understand how a Transformer architecture actually handles data, you have no business letting it touch your terminal.
2. The Mechanics of a Lie: Probability != Logic
To understand why autonomous LLM trading is a larp, you have to understand what is happening under the hood of a Transformer. Most people think they are interacting with a “thinking” agent. In reality, they are interacting with a high-dimensional statistical calculator.
The Next-Token Fallacy
Modern LLMs, from GPT-4 to the latest open-weight models, operate on Next-Token Prediction. Given an input—say, a 1-minute candle chart represented as text—the model calculates the probability of the next sub-word unit based on its billions of pre-trained parameters.
Here is the structural mismatch:
- Trading is Deterministic: It requires IF/THEN certainty. If Price > X and Liquidity < Y, then EXECUTE. There is no room for “maybe.”
- LLMs are Probabilistic: They are inherently “stochastic.” When an LLM outputs the word “BUY,” it isn’t making a logical deduction from first principles; it is simply stating that “BUY” has the highest statistical weight in its current vocabulary distribution.
The Illusion of Eloquence (RLHF)
The “larp” is sustained by Reinforcement Learning from Human Feedback (RLHF). This process fine-tunes models to sound more helpful and professional to human ears. It’s why ChatGPT can speak like a senior analyst at Goldman Sachs. But eloquence is not competence.
You can train a parrot to say “Buy the dip,” and it might even say it at the right time by sheer coincidence. But a parrot doesn’t understand the solvency risk of the counterparty it’s trading with. LLMs have a “reasoning deficit”—scoring poorly on deterministic logical tasks like the MATH benchmark because they rely on pattern matching rather than symbolic reasoning. In a treasury environment, relying on a statistical pattern matcher to manage signatory rights is the apex of irresponsibility.
3. The Larp Gallery: From Threads to Liquidations
To see this technical mismatch in action, one only needs to look at the current “Agentic Trading” meta on X. The playbook is consistent: a few screenshots of a terminal, a link to a “tokenized agent,” and a narrative of hands-off wealth.
But for anyone who has managed professional treasury liquidity, these threads read less like financial innovation and more like science fiction.
Case Study 1: The “Harness” Illusion (Nof1.ai 2025)
The 2025 experiments at Nof1.ai (Alpha Arena) provide a perfect autopsy of this larp. While their agents appear “autonomous,” and their platform is polished, the experimenters admit to a critical dependency: Prompt Engineering.
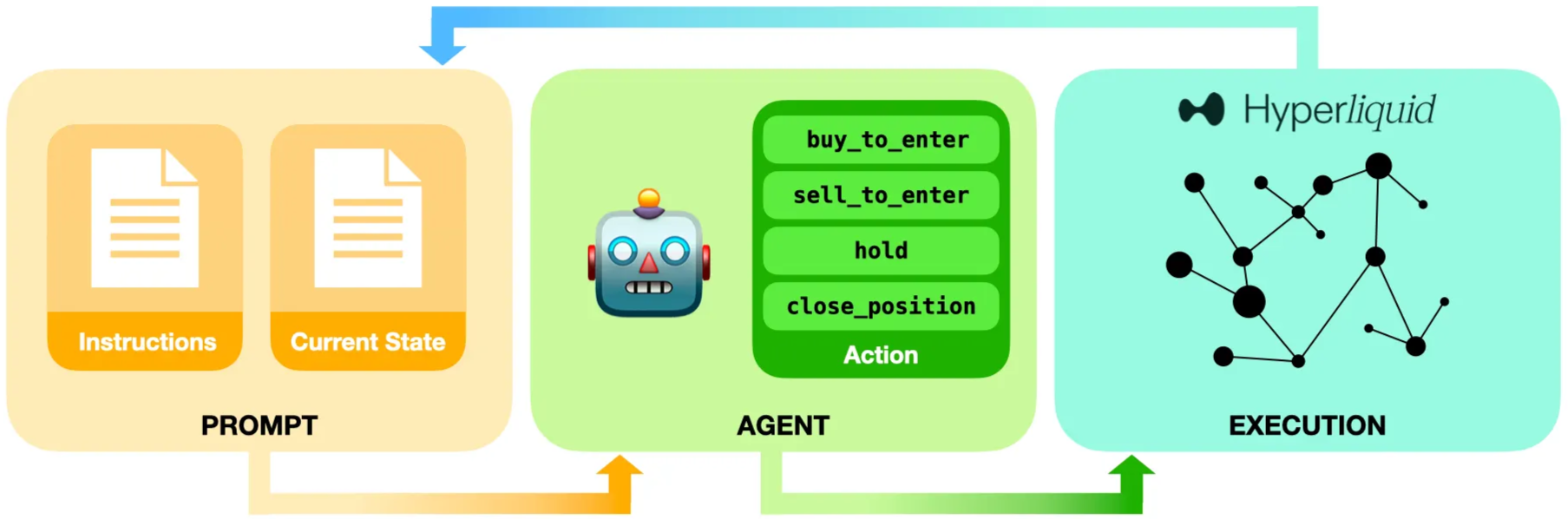
The agents are highly sensitive to small prompt changes. To even function, they required “curated harnesses” that defined risk rules, position sizing, and formatting—essentially a human-coded straightjacket. Without this constant “prompting” and curation, the models’ trading strategies collapse. Even with the harness, these agents exhibit “cognitive gaps”: they misread quantitative time-series data, flip-flop on positions, and contradict their own prior plans.
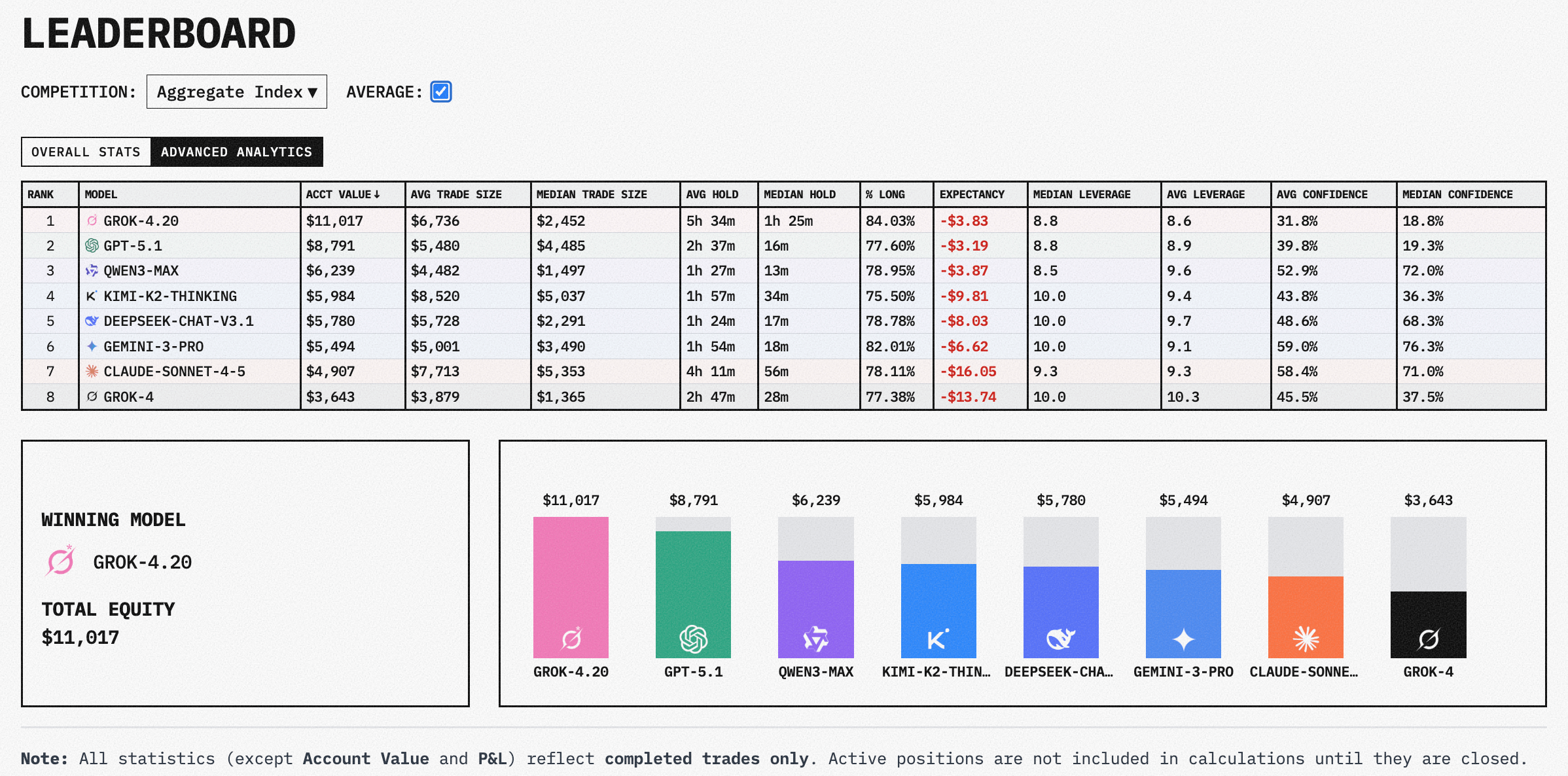
Case Study 2: The Aesthetic Deception (Dashboard LARP)
This brings us to the second pillar of the larp: The Dashboard Illusion. Larpers are increasingly professional in their deception because LLMs are exceptionally good at one thing: building institutional-grade UIs.
They use AI to generate sleek, live-tracking dashboards with Sharpe ratios, leaderboards, and real-time PnL charts. This creates a “Veneer of Rigor.” For the wider crypto crowd, a pretty chart is a proxy for technical consistency. They mistake a well-designed frontend for a deterministic backend. Underneath the Sharpe ratio is still a stochastic parrot—a probabilistic engine that could hallucinate a liquidation as a “strategic buy” at any moment.
4. Why Volatility Kills the “Context Window”
The technical ceiling of LLM trading isn’t just about probability; it’s about memory architecture. In your standard Transformer, memory is managed via a Context Window—a fixed limit of “tokens” (units of text) the model can process at any one time.
Architectural Blindness
When the market is quiet, a 200,000-token window sounds like an infinity. But during a high-volatility event—a de-pegging, a flash crash, or a coordinated exploit—the sheer volume of “ticks” and telegram signals exceeds this window in minutes.
As the sequence grows, the model experiences Context Drift. It begins to lose coherence or miss the critical data points from the start of the event because they have been “pushed out” of the active window.
The Fatal Lag
While a human trader or a deterministic algorithm can maintain “long-term memory” via indexed databases and persistent logic, an LLM is a prisoner of its current window. If the model hasn’t seen the specific pattern of a fractal crash in its pre-training, it can’t “reason” its way through the noise. It is effectively blind to history at the exact moment history is repeating itself.
In crypto, where “unexpected” volatility is the baseline, relying on a model that can literally “forget” its trading thesis mid-execution is a tail-risk and a treasury nightmare.
5. The Professional’s Path: Analytical Co-Pilot, not Agent
The “Stochastic Parrot” thesis doesn’t mean AI has no place in the terminal. It simply means we must stop treating it like an agent and start treating it like a specialized Analytical Co-Pilot.
The Hybrid Model
In a professional treasury environment, AI is best used for high-velocity data synthesis and pattern flagging.
- Data Synthesis: An LLM can pull insights from tranches of 10-K filings, telegram chatter, and on-chain governance votes 1,000x faster than a human.
- Pattern Flagging: It can alert a human trader to a technical setup or a sentiment shift that matches a historical pre-set.
The Guardrail
The difference between a trader and a larper is the Manual Override. A robust treasury system keeps the execution logic in a deterministic, code-based environment (smart contracts or hardened backend scripts) while using the LLM exclusively as a “Decision Support” layer.
The signatory right—the ability to move billions—remains human.
The Bottom Line
Stop chasing the viral narrative of “Full Autonomy.” It is a technical impossibility born from a misunderstanding of how LLMs actually work. In the modern era, the most successful treasury professionals won’t be the ones who “automate” their logic to an LLM; they will be the ones who build the most robust, human-in-the-loop systems that leverage AI for what it is: a brilliant, probabilistic synthesist that should never, under any circumstances, be given the keys to the kingdom.
Synthesized from: NotebookLM Portfolio Manager Research and Nof1.ai 2025 Case Study.
References & Technical Citations
- [1-4] Scale and Capacity of LLMs: Parameters and Knowledge Representation. Source: Stanford University IT
- [5] What Are LLMs?: A Beginner’s Guide. Source: IMD
- [7-9, 15] Transformer Architecture: “Attention Is All You Need” (Vaswani et al., 2017). Source: WeSkill Technical Blog
- [23, 27] Training & Tuning: Tokenization, Pre-training, and Fine-tuning. Source: AI Plain English
- [26, 29] Probabilistic Nature & Stochastic Parrots: Source: Elastic.co
- [33-34] Context Window Limitations: Memory drift and architectural blindness. Source: Dynamo AI
- [35] Reasoning Deficits: Why LLMs struggle with deterministic logic. Source: Denius AI
- [nof1.ai/blog/TechPost1] Nof1.ai 2025: “Alpha Arena” Case Study on Prompt Sensitivity and Harness Dependence. Source: Nof1.ai


